
Sommaires
- Introduction
- Architecture globale de Spark
- Les principaux composants de l'architecture distribuée de Spark.
- Comment une application Spark est divisée en jobs, stages et tasks.
- Spark UI
Introduction
Dans cette article nous allons voir le fonctionnement interne d’une application Spark à savoir:
- Fonctionnement d’un cluster Spark
- La relation entre le driver et les workers nodes
- La relation entre les jobs, stages et tasks
- Comment une application est divisée en jobs, stages et tasks
Architecture globale de Spark
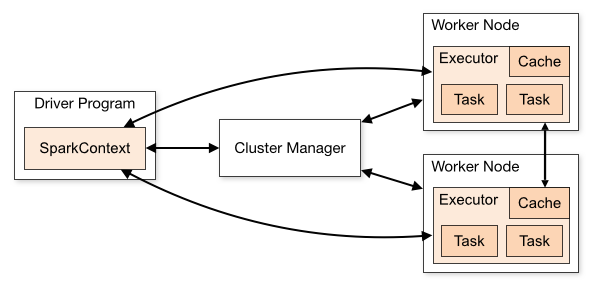
Driver Program: La class main de votre application
SparkContext: Le point d’entrée et de connexion à un cluster manager d’une application Spark. Une fois connecté, Spark acquiert des exécuteurs sur les nœuds du cluster et y envoie le code de votre application(jar ou fichier python).
Worker Node: Un nœud pouvant exécuter du code de l’application dans le cluster.
Hiérarchisation des éléments d'un cluster Spark
Pour comprendre le fonctionnement d’un cluster Spark faisons l’analogie avec un magasin de vente des téléphones.
Comptage des téléphones
Vous travailler dans un magasin de vente des téléphones portables. Votre travaille ainsi que vos collègues du même niveau hiérarchique (Manœuvre) consiste à faire du comptage des téléphones dans des cartons entassés dans une piece du magasin.
Un carton contient des téléphones de plusieurs marques: iPhone, Huawai et Samsung. Les instructions vous sont données par votre manager.
Sachant que, pour compter le nombre de téléphones dans un carton il vous faut 30 secondes.
Q1: Combien de temps il vous faudra pour compter 10 cartons ?
Q2: Combien de manœuvres faut-il pour compter 100 cartons en moins de 6O secondes ?
Q3: Vous êtes 3 combien de temps vous faudra pour compter 60 cartons ?
Q4: Quels sont les ressources nécessaires pour mener à bien ce travail ?
Les réponses:
Q1: Il faut 300 secondes (30 * 10) à un manœuvre pour compter 10 cartons.
Q2: Pour compter 100 cartons en moins de 60 secondes il vous faut au moins 50 manœuvres: en 60 secondes une manœuvre compte 2 cartons et 100/2 = 50
Q3: Il faudra 600 secondes( 60/3 * 30) a 3 manœuvres pour compter 60 cartons.
Q4: Les ressources nécessaires: Le manager, les manœuvres, des espaces pour compter, la piece contenant les cartons et les cartons.
Correspondances avec un cluster Spark
Le manager, manœuvres et leurs ressources => Cluster
Le manager dont le rôle est de donner des instructions aux manœuvres => Driver
Un groupe des manœuvres dans un espace de travail => Executor
Un manœuvre => Thread ou Slot ou Core
Un carton => partition
Dataset => Piece contenant les cartons
Ordre de compter les téléphones => Job
Une instruction à un manœuvre de traiter un carton => Task
Vous l’avez donc compris pour diminuer le temps de traitement d’un nombre important de cartons nous avons besoin d’augmenter le nombre de manœuvres.
Hiérarchie des éléments d'un cluster Spark.
Le traitement d’un Dataset au sein d’un cluster Spark est effectué de la manière suivante:
Le Dataset est divisé en plusieurs partitions. Une partition est un ensemble des données traitées ensemble par un Thread associé à un task.
Job => Stages = > tasks
Le Job: constitue l’action à effectuer: compter les iPhones dans une pièce. Le Job est divisé en petits ensembles de tasks appelées Stage qui dépendent les unes des autres (A cause du shuffle que nous allons voir dans un prochain chapitre).
Etudions un bout de code
Le fichier people.txt dans votre répertoire Spark (répertoire où Spark est installé) contient le nom et l’age de 3 personnes:
head examples/src/main/resources/people.txt
Michael, 29
Andy, 30
Justin, 19
val peopleRDD = spark.sparkContext.textFile("examples/src/main/resources/people.txt")peopleRDD.map(_.split(",")).map(p => p(1).trim.toInt).reduce((age1,age2) => age1 + age2)
res33: Int = 78
Ce bout de code calcul la somme des âges des 3 personnes.
Regardons à présent l’interface Spark UI.
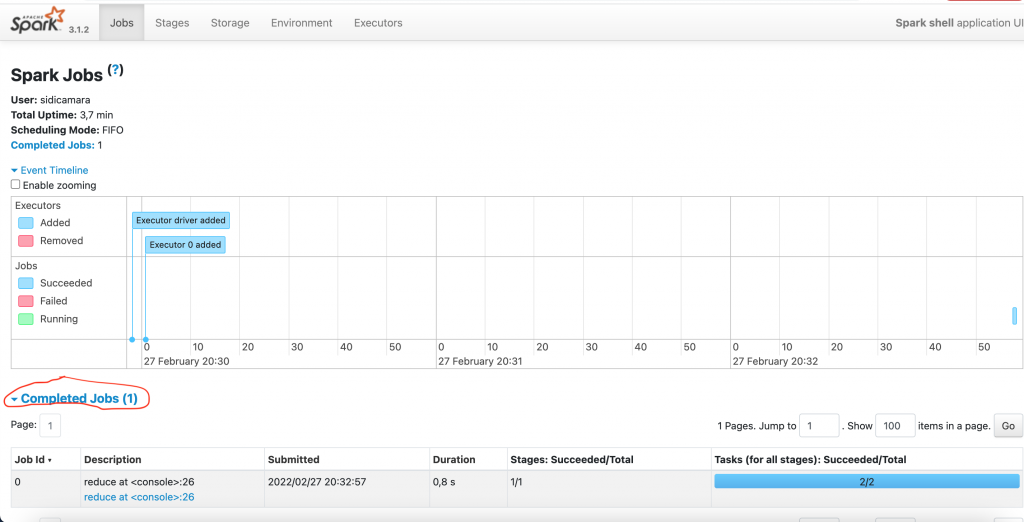
Un job a été lancé dans le cluster.
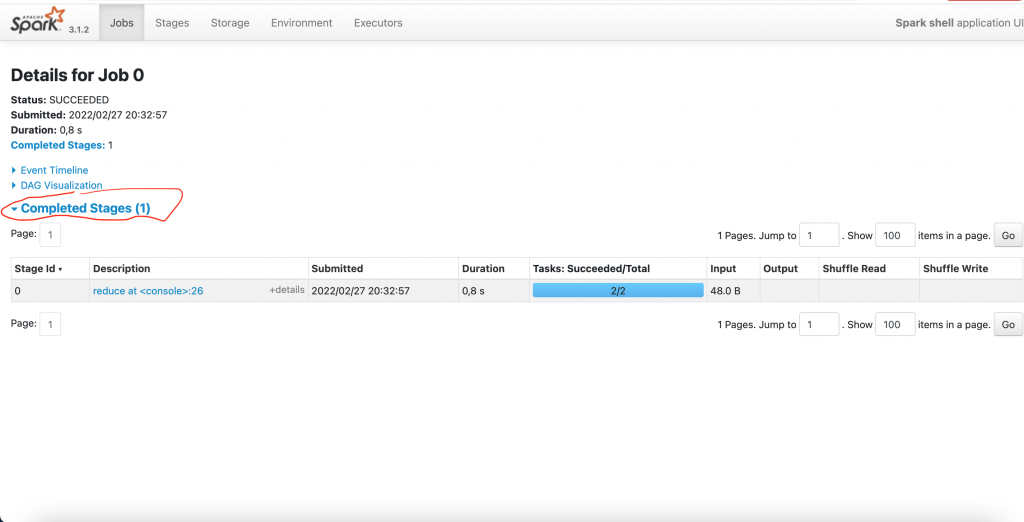
Le Job a un Stage
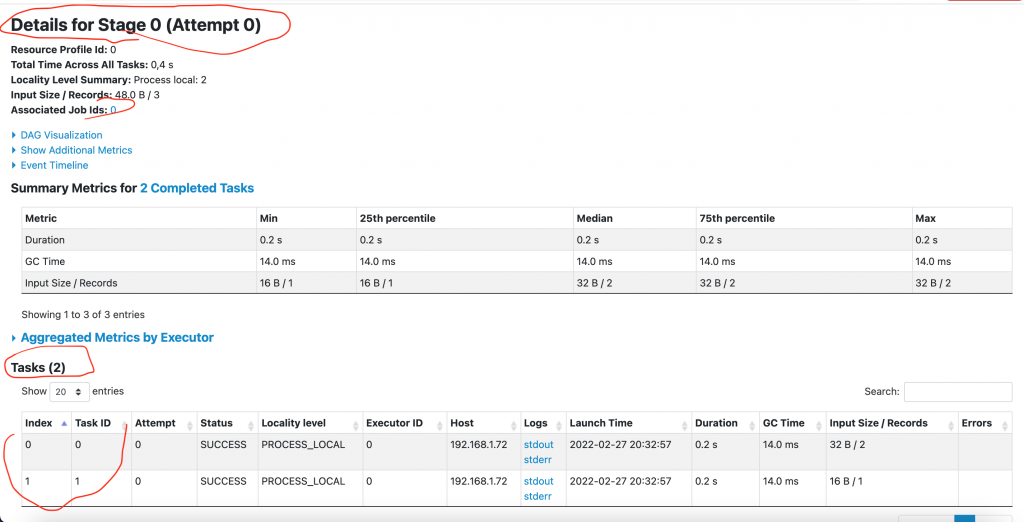
Le Stage a 2 Tasks
Maintenant exécutons le bout de code suivant.
peopleRDD.map(_.split(",")).map(p => p(1).trim.toInt).groupBy(x => x % 2).collect()
La sortie
res1: Array[(Int, Iterable[Int])] = Array((0,CompactBuffer(30)), (1,CompactBuffer(29, 19)))
Le code groupe les personnes dans 2 listes: ‘âge pair et impair.
Nous avons le Spark UI suivant
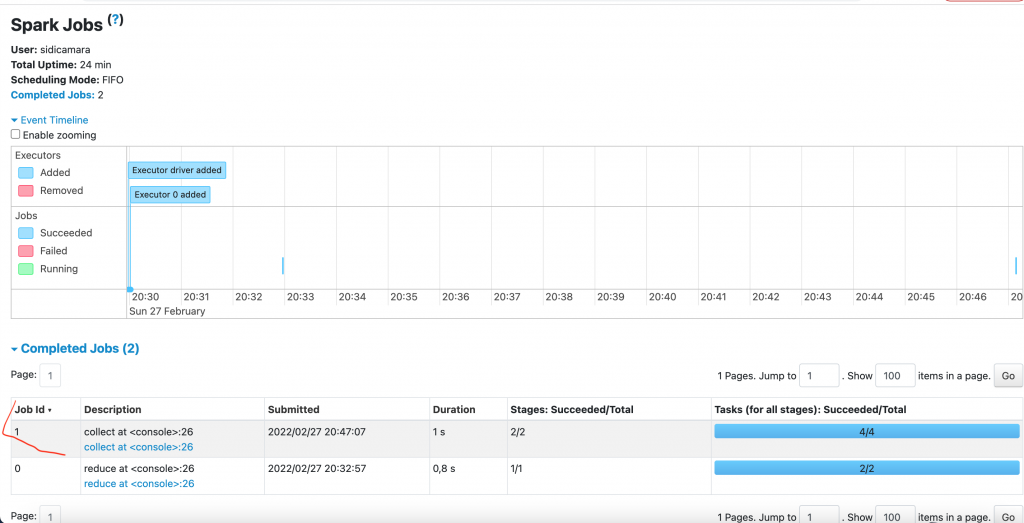
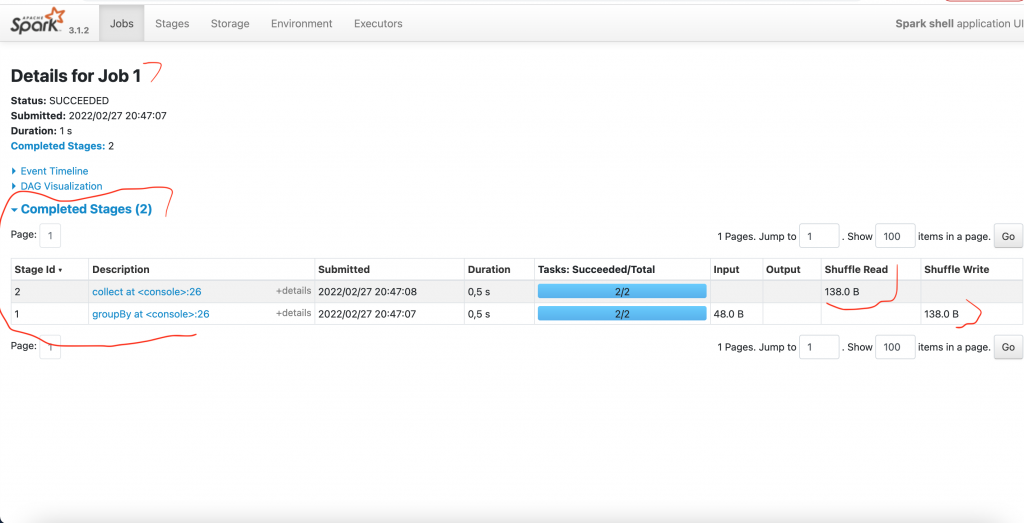
Cette opération a engendré 2 Stages. On remarque également qu’il y’a eu du Shuffle.
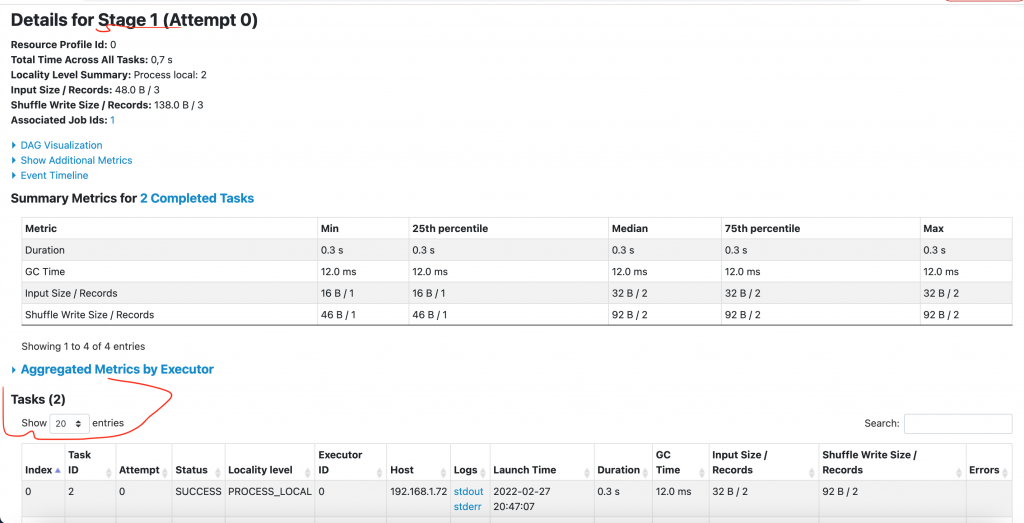
Le Stage 1 a 2 Tasks